Design Solution
With supermarkets constantly changing and importing new products, it is necessary to train a network that is able to detect objects based on very few examples and identify unseen classes. My solution involves using the Siamese Network, which performs a convolutional neural network on two images and output a similarity score based on their feature vectors.
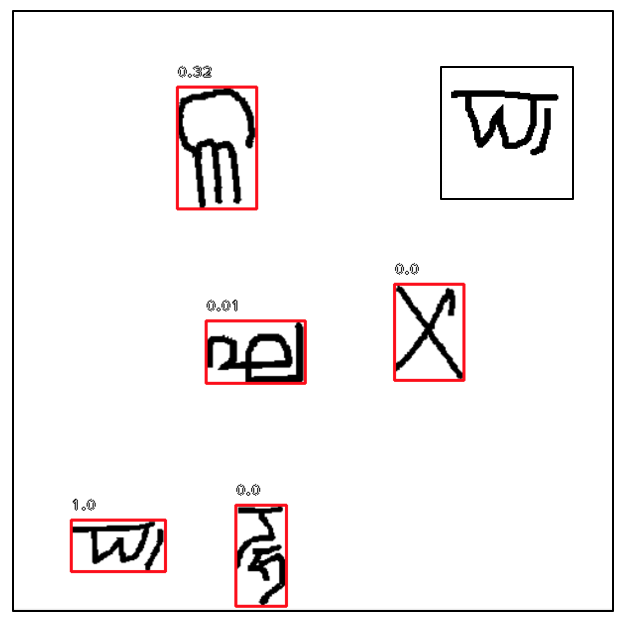
The Siamese Network performs one-shot learning classification tasks, which makes a prediction on an test instance after observing only one example from each class. I was able to incorporate this method into a current state-of-the-art object detection network, RetinaNet. RetinaNet is faster than other region-based algorithms while achieving very high accuracies.
I annotated my own training and testing images using the Omniglot dataset, which consists of over 1600 characters and 20 examples of each. Compared to the baseline accuracy of 71.88% obtained from passing the inputs into the two networks separately, my network achieved a 89.43% performance.